Introduction
The liver is a vital organ in the human body, playing a crucial role in various functions that contribute to metabolism, immunity, digestion, detoxification, and vitamin storage, among others. It makes up approximately 2% of an adult’s total body weight. One of the unique features of the liver is its dual blood supply, which comes from two sources: the portal vein supplies about 75% of the blood, while the hepatic artery provides the remaining 25%. The liver consists of four lobes: the larger right lobe and left lobe, and the smaller caudate lobe and quadrate lobe. The left and right lobe are divided by the falciform (“sickle-shaped” in Latin) ligament, which connects the liver to the abdominal wall. The liver’s lobes can be further divided into eight segments, which are made up of thousands of lobules (small lobes). Each of these lobules has a duct flowing toward the common hepatic duct, which drains bile from the liver.

HSA KIT
The HSA KIT software offers an intuitive user interface along with advanced professional annotation features, ensuring precision down to the finest pixel detail. Through process standardization, consistency maintenance, and support for reproducibility, it significantly elevates the overall analysis procedure.
The Liver Model focuses on detection of two most important structures for the study of Liver organ:
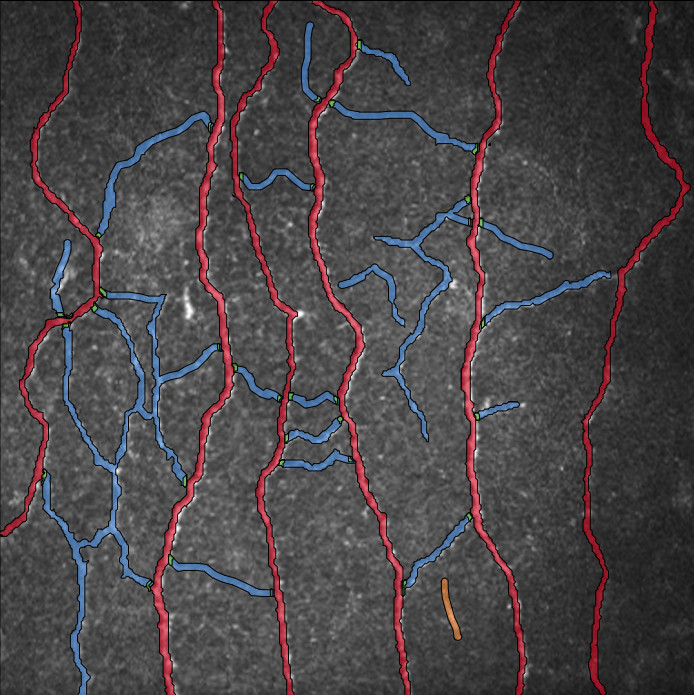
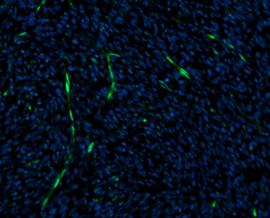
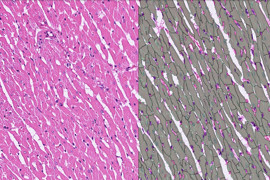
- Vessels: In the context of a liver project, “Vessels” typically refers to blood vessels within the liver. Blood vessels play a crucial role in transporting blood throughout the liver, and their analysis can provide insights into the organ’s health and function. Annotating vessels in liver images can help in identifying their distribution, structure, and potential abnormalities, aiding in diagnostic and research purposes
- Non-Vessels: Refers to areas within the liver images that are not part of the blood vessel network. These could include various tissues, organs, structures, or even artifacts that are present in the images but do not correspond to blood vessels.
Zoom Out View


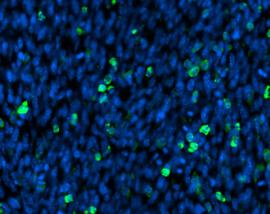
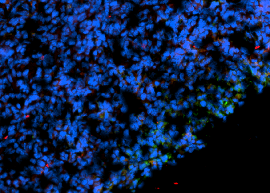
Zoomed In View – Negative Cells


Zoomed In View – Positive Cells


Zoomed In View – Uncertain Cells


Functions of the Liver
The liver serves several vital functions, including:
- Detoxification: The liver filters toxins and harmful substances out of the blood. It removes compounds from the body, including hormones, such as estrogen and aldosterone, and compounds from outside the body, including alcohol and other drugs.
- Bile Production: The liver produces bile, a fluid that helps the body digest (break down) food. Bile consists of bile salts, cholesterol, bilirubin, electrolytes, and water also mention in figure 1.
- Metabolism: The liver metabolizes proteins, carbohydrates, and fats so the body can use them. It also plays a role in heme breakdown into unconjugated bilirubin and conjugates it.
- Blood Regulation: The liver regulates most chemical levels in the blood. It stores iron and copper and plays a role in hematology with clotting factor and protein synthesis. The liver also regulates blood sugar levels and produces substances to help blood clot.

The most common Liver Diseases
Hepatitis is a broad term used to refer to the inflammation of the liver. This inflammation can occur due to various factors, including viral infections (viral hepatitis), exposure to certain chemicals or drugs, excessive alcohol consumption, specific genetic disorders, or an autoimmune response where the immune system erroneously targets and attacks the liver, leading to autoimmune hepatitis.
1- Hepatitis A: This highly contagious virus is spread mainly through contaminated food or water. It is an acute, short-term type of hepatitis that usually does not require treatment as it goes away on its own with no long-term effect.
2- Hepariris B: Infection occurs through the spread of bodily fluids such as blood and semen. It can cause an acute (short-term) or chronic (long-term) infection. Often acute infections require no treatment and improve on their own. Some chronic infections will require treatment to help with the symptom severity.
Fatty lever disease: is a condition in which too much fat builds up in your liver, of which there are two main types:
- Nonalcoholic Fatty Liver Disease (NAFLD):
- NAFLD is not associated with heavy alcohol consumption.
- In its early stage, it is known as simple fatty liver, characterized by fat buildup without inflammation or liver cell damage.
- If inflammation and liver cell damage occur, it progresses to nonalcoholic steatohepatitis (NASH), which can lead to liver fibrosis or scarring (cirrhosis).
Liver cancer : Cancer is broadly described as a disease that happens when abnormal cells grow too quickly, leaving less space for normal cells. There are two types of liver cancer, primary and secondary.
Whole slide images (WSI)

The first WSI scanners, introduced in the late 1990s, were quite primitive compared with their contemporary counterparts.7 Prior to the introduction of WSI, digital imaging in anatomic pathology relied largely on microscope mounted cameras to produce “static” digital images.2 These static images were of limited clinical utility because they captured only specific regions of a glass slide. Robotic microscopy was accordingly utilized because it allowed the telepathologist to remotely review an entire glass slide.
Whole slide imaging (WSI) is a technology that involves scanning a complete microscope slide and creating a single high-resolution digital file. whole slide imaging offers numerous advantages in pathology, including improved collaboration, accessibility, efficiency, archiving, and education. It is a valuable tool that is transforming the field of pathology. Deep learning has been applied to WSI for various tasks, including segmentation and analysis of liver images.
Digitlaization of slide
The process of digitizing slides is accomplished through the utilization of the software HSA SCAN, a creation of HS Analysis GmbH. HSA SCAN serves the purpose of transforming physical slides into digital files. Additionally, the procedure involves the utilization of the HSA SCANNER, a hardware product designed to convert an analog microscope into a digital one economically.

The first step is to turn on the microscopy and then place the slide underneath it, adjusting the appropriate lens.

The second step involves modifying the computer settings to display the scan.

The next step involves initiating the scanning process for the slide until every part of the scan is completed.

HSA simplifies the process by requesting the microscope’s dimensions and any necessary specifications. Once provided, a custom-fit stand and motor tailored for the microscope are delivered. This eliminates the requirement for manual adjustments, guaranteeing consistent outcomes.
The benefits include:
- Accurate and Swift Scanning: Achieving precise and rapid scans.
- Budget-Friendly: Offers cost advantages compared to automated scanners.
- Time Efficiency: Automates tasks that traditionally need manual intervention.
- Enhanced Workflow and Quality: Reduces the likelihood of errors or inconsistencies.
- Intuitive Controls: User-friendly interface, accessible even to those with limited microscope experience.
Stochastic Gradient Descent (SGD)
The term ‘stochastic’ refers to a system or process connected with random probabilities. Stochastic gradient descent leverages this concept to expedite the gradient descent process. In contrast to standard Gradient Descent (SGD), where the entire dataset is used in each iteration, stochastic gradient descent utilizes the cost gradient of just one example per iteration.[41]
The three main types of Gradient Descent are Batch Gradient Descent, Stochastic Gradient Descent, and Mini-batch Gradient Descent. The choice between Batch Gradient Descent, Stochastic Gradient Descent, and Mini-batch Gradient Descent depends on the size of the dataset, the computational resources available, and the optimization problem at hand. Stochastic Gradient Descent (SGD) key benefit lies in its computational efficiency, particularly for large datasets. Unlike traditional Gradient Descent, which requires processing the entire dataset, SGD processes just one data point or a small batch per iteration. This significantly reduces the computational cost and accelerates convergence. find the optimal values of the parameters of a model that minimize a cost function
Encoder-Decoder Structure
An encoder-decoder model in machine learning is a type of neural network architecture that processes an input sequence and converts it into a fixed-length internal representation called the context vector, which is then passed to a decoder that generates an output sequence.
The Encoder-Decoder architecture finds wide use in image processing, particularly in tasks like image segmentation. In this scenario, it takes an image as input and generates a segmented image as output. This architecture essentially employs a deep convolutional neural network to achieve this transformation

There are several advantages to implementing an encoder-decoder architecture with Recurrent Neural Networks (RNNs):
- Flexibility: Encoder-Decoder RNNs can be used for various tasks, such as machine translation, text summarization, and image captioning.
- Handling variable-length input and the output: Encoder-Decoder RNNs are particularly useful for tasks with different lengths of input and output sequences.
- Handling sequential data: RNNs are particularly well-suited for handling sequential data.
- Handling missing data: Encoder-Decoder RNNs can handle missing data by only passing the available data to the encoder.
Consequently, the encoder-decoder structure allows us to extract the most info from a picture and generate valuable correlations between various inputs inside The network
Digital Representation of Images
A digital image is a representation of a real image as a set of numbers that can be stored and handled by a digital computer. In order to translate the image into numbers, it is divided into small areas called pixels (picture elements). For each pixel, the imaging device records a number, or a small set of numbers, that describe some property of this pixel, such as its brightness (the intensity of the light) or its color. The numbers are arranged in an array of rows and columns that correspond to the vertical and horizontal positions of the pixels in the image.
Digital representation of images is an important tool in the detection and analysis of liver diseases. Here are some examples of how digital imaging analysis has been used in liver disease research:
Deep Learning in Liver Diseases: Deep learning algorithm performance evaluation in detection of liver cancer in hepatitis patients
Mean Average Precision (mAP)
Mean Average Precision (mAP), a widely used metric in evaluating machine learning models. mAP plays a crucial role in benchmark challenges like PASCAL VOC, COCO, and others. It measures the overall performance of a model across different categories, providing a balanced view of its accuracy. By averaging the Average Precision values for each class, mAP offers a comprehensive understanding of a model’s ability to handle various categories effectively.[62]
mAP formula is based on the following sub metrics:
- Confusion Matrix,
- Intersection over Union(IoU),
- Recall,
- Precision
Precision is the ratio of correctly predicted positives and predicted positives. More specifically, precision tells us how many objects we classify as positive belong to the positive class.
Here are the steps to calculate the AP
- Generate the prediction scores using the model.
- Convert the prediction scores into class labels.
- Compute the TP, FP, TN, and FN confusion matrices.
- Determine the precision and recall metric.
- Determine the region beneath the precision-recall curve.
Calculate the average precision
Workflow with HSA KIT
Analyzing samples and digitizing slides has never been more effortless. HSA KIT offers an unparalleled experience to its customers who seek to embrace more advanced alternatives and enhance their workflow efficiency. The HSA team goes to great lengths to satisfy its clients, assisting with software installation, integration, and providing continuous support and updates.
Using AI-based analysis with HSA KIT, you can expect:
- Standardized processes encompassing both subjective and objective analysis.
- Extraction of pertinent features from raw data, generating meaningful representations for training AI models.
- Module selection and configuration without the need for extensive coding.
- User-friendly software that is easy to learn, enabling annotation, training, and automation.
- Swift and effective analysis of numerous medical images, reducing diagnosis or treatment time.
- Automated report generation to enhance productivity and aid physicians or radiologists in the evaluation process.

Feature Extraction
Feature extraction is a process of transforming raw data into numerical features that can be processed while preserving the information in the original data set. It is a crucial step in machine learning, pattern recognition, and image processing.
Feature extraction is a crucial step in data analysis and machine learning, enabling more efficient and effective processing of large datasets.
Feature extraction is particularly useful when working with large amounts of data in machine learning, where it can be a tedious task to process all the input data. By summarizing the original features into a smaller set of meaningful groups, feature extraction helps to reduce the amount of time and storage required to process the data.

Deep learning (DL)
Artificial intelligence (AI) and machine learning techniques called deep learning model how people acquire specific types of information. Deep learning models can be instructed to carry out classification tasks and spot patterns in images, text, audio, and other types of data. Additionally, it is utilized to automate jobs that ordinarily call for human intellect, such annotating photographs or transcribing audio files.
Machine learning (ML) is a subset of AI in which algorithms are trained to solve tasks through feature learning instead of an explicit rules-based approach. When presented with a “training” cohort, the algorithm identifies salient features, which are subsequently used to make predictions. Hence, the “machine” “learns” from the data itself.
Deep learning is an important element of data science, including statistics. It is extremely beneficial to data scientists who are tasked with collecting, analyzing and interpreting large amounts of data; deep learning makes this process faster and easier. [5] Machine learning and deep learning are both subsets of artificial intelligence (AI) and are used to train computer systems to perform tasks without being explicitly programmed. However, there are some differences between the two. Machine learning is a type of AI that enables computers to learn from data using algorithms and to perform a task without being explicitly programmed. It can be supervised, unsupervised, or semi-supervised. In supervised learning, the algorithm is trained on labeled data, while in unsupervised learning, the algorithm is trained on unlabeled data.

Regularization
Regularization involves constraining a model to prevent overfitting by reducing the magnitude of coefficient estimates toward zero. When a model grapples with overfitting, it’s crucial to rein in its complexity. In practice, regularization tackles overfitting by introducing an additional term in the model’s loss function, essentially imposing a penalty.
Overfitting and underfitting are common problems in machine learning that can harm a model’s accuracy. Overfitting occurs when a model learns from noise instead of real patterns in data. Underfitting happens when a model is too simple to grasp the main trends in the data. Underfitting is linked to high bias and low variance, often caused by a model’s simplicity or insufficient data. Remedies involve increasing model complexity, adding pertinent features, minimizing data noise, and extending training duration. Overfitting is tied to high variance and low bias, often driven by model complexity or limited data. Solutions encompass expanding the training dataset, reducing model complexity, early stopping, Ridge, and Lasso regularization, and incorporating dropout in neural networks.

Bias: refers to the assumptions a model makes to simplify learning a function. It’s the training data’s error rate. When this error rate is high, it’s termed High Bias, and when it’s low, it’s Low Bias.
Variance: represents the difference between error rates in training and testing data. If this difference is high, it’s High Variance; when it’s low, it’s Low Variance. Generally, we aim for low variance to ensure a well-generalized model
Creation of ground-truth data
The samples that used in this work were prepared by HS Analysis GmbH company customer. The samples were taken from died mouse liver by slicing, preparing slides, staining cells, then converting the slides to digital CZI files by scanning and finally sent the CZI files to company to make DL model. To have a DL model, The first stage of model development requires the creation of a ground truth dataset (GTD), The following steps are involved:
- The CZI files were loaded into the HSA KIT software.
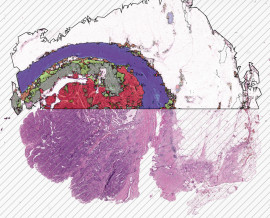
- An area for creating Ground Truth Data (GTD) was selected, ensuring that the area was not situated at the edge of the sample. This area of interest was then identified using the Region of Interest (ROI) tool.
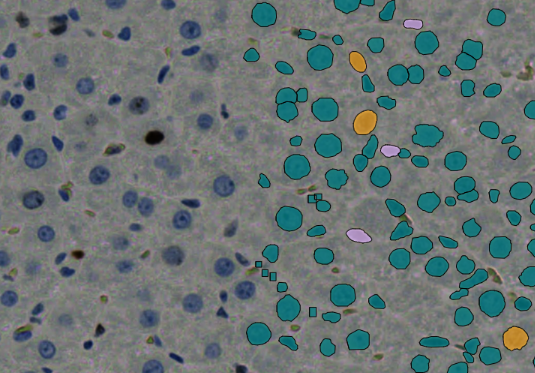
- The target area, which includes both ‘Vessels’ and ‘Non-Vessels,’ was annotated within the selected ROI region.
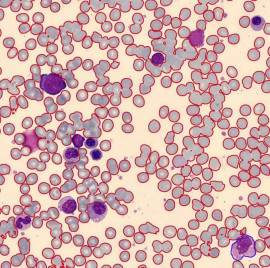
- The ‘Non-Vessels’ category was further divided into sub-classes such as ‘Cell Positive,’ ‘Cell Negative,’ and ‘Uncertain Cell.’
- This annotated data was utilized to train the Deep Learning (DL) model using the HSA KIT software.
After the Ground Truth Data (GTD) was created, the model was trained (the results are explained in Chapter 4). Subsequently, additional GTD was generated to enhance the model’s performance. Initially, the model was trained using 724 GTD, focusing on broader areas like ‘Vessels’ and ‘Non-Vessels.’ The second time around, the model was trained with 6,139 GTD (6.1K), targeting more specific areas like ‘Cell Positive,’ ‘Cell Negative,’ and ‘Uncertain Cells.’ The distribution of classes and their corresponding percentages in the data set are provided in Table 1 and Table 2.
| Amount of GTD | File Number | Vessels | Non vessels | |||
| Object | Percentage | Object | Percentage | |||
| 724 | 1st File | 292 | % | 14 | % | |
| 2st file | 402 | % | 16 | % | ||
Table 1: The number of Vessels & Non vessels used in this work
| Amount of GTD | File Number | Cell positive | Cell negative | Uncertain cells | ||||
| Object | Percentage | Object | Percentage | Object | Percentage | |||
| 6.1K | 1st File | 345 | % | 5459 | % | 335 | % | |
Table 2: The number of Sub-cells used in this work.
Ground truth” is a term commonly used in statistics and machine learning. It refers to the correct or “true” answer to a specific problem or question. It is a “gold standard” that can be used to compare and evaluate model results.
Why is Ground Truth Important in Machine Learning?
~ Ground truth data is crucial for both model training and testing in AI development. It helps the algorithm learn and improve during training and provides a reliable benchmark to assess its accuracy during testing.
~ During model training, ground truth data is used to teach the algorithm which features and solutions are appropriate for the specific application. During model testing, the trained algorithm is tested for model accuracy using ground truth data.
The GTD table presents a structured overview of annotations and their associations with different files, classes, and projects, primarily within the context of liver analysis. This data aims to provide insights into the distribution of annotations among various categories.
For each file, the table provides information about the relevant class and project that the annotations pertain to. The primary class is denoted, which, in this case, includes “Vessel” and “Non-vessel” classes. The primary project is “Liver.”
To determine if the data is balanced or not, we need to consider the distribution of annotations across classes and projects. From the my information above table , it appears that the annotations are not evenly distributed across classes and projects. Some classes have a significantly larger number of annotations than others. For example, the “Cells blue” class has a much higher number of annotations compared to the “Cell browin ” class in several cases.
Human-Machine Interaction (HMI)
The annotation tool is used to make and classify the Ground Truth Data (GTD) which usually consists of hundreds to thousands of data. The quality of the generated data is important for the accuracy of the segmentation, and the quality of the DL model can only be as good as the quality of the GTD. The HSA KIT software is designed to integrate seamlessly into existing laboratory information systems, enabling seamless data exchange and precision through human-machine interaction (HMI). This means that modifications can be made at any moment in case of discontent.
Title: Annotating Liver Projects with “HSA KIT”: Precision and Efficiency
“HSA KIT” software—a powerful solution designed to elevate annotation precision and analysis efficiency. With its user-friendly interface and advanced annotation features, it ensures meticulous detail down to the pixel level. By standardizing processes, maintaining consistency, and supporting reproducibility, HSA KIT transforms analysis workflows. Within the Liver Model, it focuses on the essential structures for liver study: “Vessels” encompassing blood vessels crucial for circulation, and “Non-Vessels” representing diverse liver components. Additionally, the “Cell Class” feature distinguishes between “Positive” and “Negative” cells, enhancing the depth of analysis.